Endpointing
We have three rules for endpoint detection. If any of them is activated, we assume an endpoint is detected.
Note
We borrow the implementation from
https://kaldi-asr.org/doc/structkaldi_1_1OnlineEndpointRule.html
Rule 1
In Rule 1, we count the duration of trailing silence. If it is larger than
a user specified value, Rule 1 is activated. The following is an example,
which uses 2.4 seconds as the threshold.
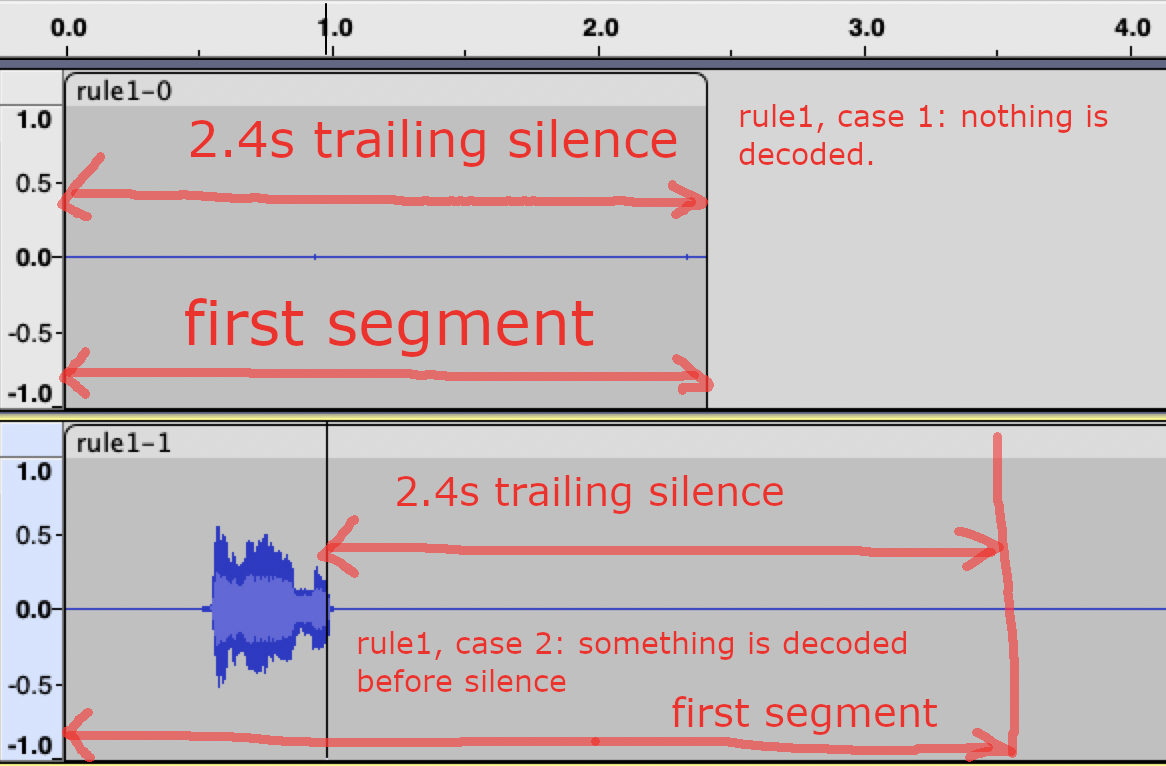
Two cases are given:
In the first case, nothing has been decoded when the duration of trailing silence reaches 2.4 seconds.
In the second case, we first decode something before the duration of trailing silence reaches 2.4 seconds.
In both cases, Rule 1 is activated.
Hint
In the Python API, you can specify rule1_min_trailing_silence while
constructing an instance of sherpa_ncnn.Recognizer.
In the C++ API, you can specify rule1.min_trailing_silence when creating
EndpointConfig.
Rule 2
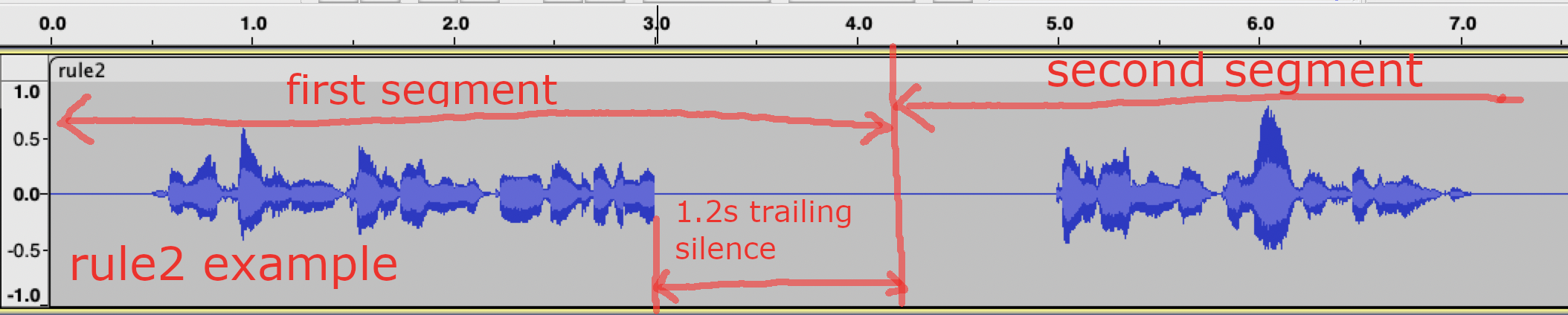
In Rule 2, we require that it has to first decode something
before we count the trailing silence. In the following example, after decoding
something, Rule 2 is activated when the duration of trailing silence is
larger than the user specified value 1.2 seconds.
Hint
In the Python API, you can specify rule2_min_trailing_silence while
constructing an instance of sherpa_ncnn.Recognizer.
In the C++ API, you can specify rule2.min_trailing_silence when creating
EndpointConfig.
Rule 3
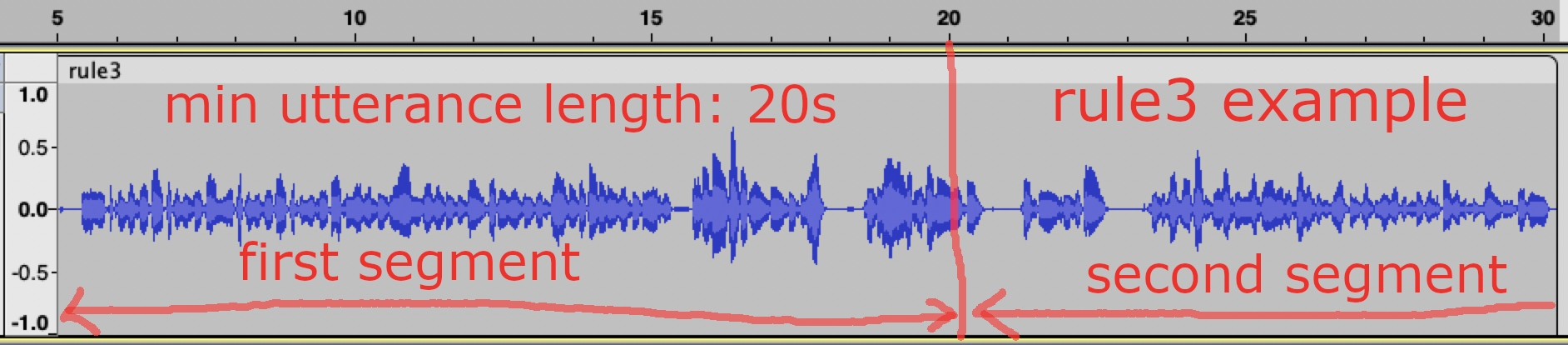
Rule 3 is activated when the utterance length in seconds is larger than
a given value. In the following example, Rule 3 is activated after the
first segment reaches a given value, which is 20 seconds in this case.
Hint
In the Python API, you can specify rule3_min_utterance_length while
constructing an instance of sherpa_ncnn.Recognizer.
In the C++ API, you can specify rule3.min_utterance_length when creating
EndpointConfig.
Note
If you want to disable this rule, please provide a very large value
for rule3_min_utterance_length or rule3.min_utterance_length.
Demo
Multilingual (Chinese + English)
The following video demonstrates using the Python API of sherpa-ncnn for real-time speech recogntinion with endpointing.
FAQs
How to compute duration of silence
For each frame to be decoded, we can output either a blank or a non-blank token.
We record the number of contiguous blanks that has been decoded so far.
In the current default setting, each frame is 10 ms. Thus, we can get
the duration of trailing silence by counting the number of contiguous trailing
blanks.
Note
If a model uses a subsampling factor of 4, the time resolution becomes
10 * 4 = 40 ms.