Conformer CTC
This tutorial shows you how to run a conformer ctc model with the Aishell dataset.
Hint
We assume you have read the page Installation and have setup
the environment for icefall.
Hint
We recommend you to use a GPU or several GPUs to run this recipe.
In this tutorial, you will learn:
How to prepare data for training and decoding
How to start the training, either with a single GPU or multiple GPUs
How to do decoding after training, with ctc-decoding, 1best and attention decoder rescoring
How to use a pre-trained model, provided by us
Data preparation
$ cd egs/aishell/ASR
$ ./prepare.sh
The script ./prepare.sh handles the data preparation for you, automagically.
All you need to do is to run it.
The data preparation contains several stages, you can use the following two options:
--stage
--stop-stage
to control which stage(s) should be run. By default, all stages are executed.
For example,
$ cd egs/aishell/ASR
$ ./prepare.sh --stage 0 --stop-stage 0
means to run only stage 0.
To run stage 2 to stage 5, use:
$ ./prepare.sh --stage 2 --stop-stage 5
Hint
If you have pre-downloaded the Aishell
dataset and the musan dataset, say,
they are saved in /tmp/aishell and /tmp/musan, you can modify
the dl_dir variable in ./prepare.sh to point to /tmp so that
./prepare.sh won’t re-download them.
Hint
A 3-gram language model will be downloaded from huggingface, we assume you have
installed and initialized git-lfs. If not, you could install git-lfs by
$ sudo apt-get install git-lfs
$ git-lfs install
If you don’t have the sudo permission, you could download the
git-lfs binary here, then add it to you PATH.
Note
All generated files by ./prepare.sh, e.g., features, lexicon, etc,
are saved in ./data directory.
Training
Configurable options
$ cd egs/aishell/ASR
$ ./conformer_ctc/train.py --help
shows you the training options that can be passed from the commandline. The following options are used quite often:
--exp-dirThe experiment folder to save logs and model checkpoints, default
./conformer_ctc/exp.
--num-epochsIt is the number of epochs to train. For instance,
./conformer_ctc/train.py --num-epochs 30trains for 30 epochs and generatesepoch-0.pt,epoch-1.pt, …,epoch-29.ptin the folder set by--exp-dir.
--start-epochIt’s used to resume training.
./conformer_ctc/train.py --start-epoch 10loads the checkpoint./conformer_ctc/exp/epoch-9.ptand starts training from epoch 10, based on the state from epoch 9.
--world-sizeIt is used for multi-GPU single-machine DDP training.
If it is 1, then no DDP training is used.
If it is 2, then GPU 0 and GPU 1 are used for DDP training.
The following shows some use cases with it.
Use case 1: You have 4 GPUs, but you only want to use GPU 0 and GPU 2 for training. You can do the following:
$ cd egs/aishell/ASR $ export CUDA_VISIBLE_DEVICES="0,2" $ ./conformer_ctc/train.py --world-size 2Use case 2: You have 4 GPUs and you want to use all of them for training. You can do the following:
$ cd egs/aishell/ASR $ ./conformer_ctc/train.py --world-size 4Use case 3: You have 4 GPUs but you only want to use GPU 3 for training. You can do the following:
$ cd egs/aishell/ASR $ export CUDA_VISIBLE_DEVICES="3" $ ./conformer_ctc/train.py --world-size 1Caution
Only multi-GPU single-machine DDP training is implemented at present. Multi-GPU multi-machine DDP training will be added later.
--max-durationIt specifies the number of seconds over all utterances in a batch, before padding. If you encounter CUDA OOM, please reduce it. For instance, if your are using V100 NVIDIA GPU, we recommend you to set it to
200.Hint
Due to padding, the number of seconds of all utterances in a batch will usually be larger than
--max-duration.A larger value for
--max-durationmay cause OOM during training, while a smaller value may increase the training time. You have to tune it.
Pre-configured options
There are some training options, e.g., weight decay,
number of warmup steps, etc,
that are not passed from the commandline.
They are pre-configured by the function get_params() in
conformer_ctc/train.py
You don’t need to change these pre-configured parameters. If you really need to change
them, please modify ./conformer_ctc/train.py directly.
Caution
The training set is perturbed by speed with two factors: 0.9 and 1.1.
Each epoch actually processes 3x150 == 450 hours of data.
Training logs
Training logs and checkpoints are saved in the folder set by --exp-dir
(default conformer_ctc/exp). You will find the following files in that directory:
epoch-0.pt,epoch-1.pt, …These are checkpoint files, containing model
state_dictand optimizerstate_dict. To resume training from some checkpoint, sayepoch-10.pt, you can use:$ ./conformer_ctc/train.py --start-epoch 11
tensorboard/This folder contains TensorBoard logs. Training loss, validation loss, learning rate, etc, are recorded in these logs. You can visualize them by:
$ cd conformer_ctc/exp/tensorboard $ tensorboard dev upload --logdir . --name "Aishell conformer ctc training with icefall" --description "Training with new LabelSmoothing loss, see https://github.com/k2-fsa/icefall/pull/109"It will print something like below:
TensorFlow installation not found - running with reduced feature set. Upload started and will continue reading any new data as it's added to the logdir. To stop uploading, press Ctrl-C. New experiment created. View your TensorBoard at: https://tensorboard.dev/experiment/engw8KSkTZqS24zBV5dgCg/ [2021-11-22T11:09:27] Started scanning logdir. [2021-11-22T11:10:14] Total uploaded: 116068 scalars, 0 tensors, 0 binary objects Listening for new data in logdir...Note there is a URL in the above output, click it and you will see the following screenshot:
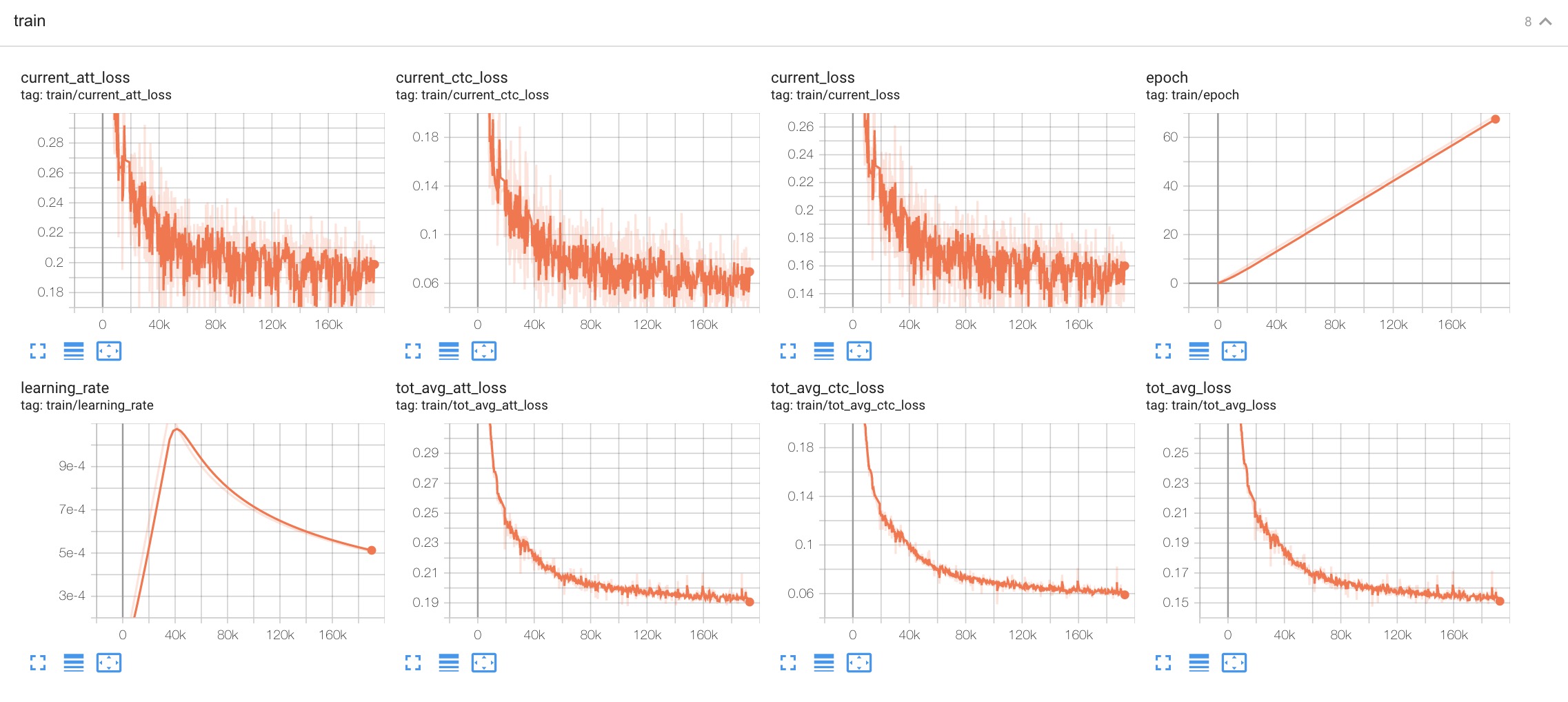
Fig. 2 TensorBoard screenshot.
log/log-train-xxxxIt is the detailed training log in text format, same as the one you saw printed to the console during training.
Usage examples
The following shows typical use cases:
Case 1
$ cd egs/aishell/ASR
$ ./conformer_ctc/train.py --max-duration 200
It uses --max-duration of 200 to avoid OOM.
Case 2
$ cd egs/aishell/ASR
$ export CUDA_VISIBLE_DEVICES="0,3"
$ ./conformer_ctc/train.py --world-size 2
It uses GPU 0 and GPU 3 for DDP training.
Case 3
$ cd egs/aishell/ASR
$ ./conformer_ctc/train.py --num-epochs 10 --start-epoch 3
It loads checkpoint ./conformer_ctc/exp/epoch-2.pt and starts
training from epoch 3. Also, it trains for 10 epochs.
Decoding
The decoding part uses checkpoints saved by the training part, so you have to run the training part first.
$ cd egs/aishell/ASR
$ ./conformer_ctc/decode.py --help
shows the options for decoding.
The commonly used options are:
--methodThis specifies the decoding method.
The following command uses attention decoder for rescoring:
$ cd egs/aishell/ASR $ ./conformer_ctc/decode.py --method attention-decoder --max-duration 30 --nbest-scale 0.5
--nbest-scaleIt is used to scale down lattice scores so that there are more unique paths for rescoring.
--max-durationIt has the same meaning as the one during training. A larger value may cause OOM.
Pre-trained Model
We have uploaded a pre-trained model to https://huggingface.co/pkufool/icefall_asr_aishell_conformer_ctc.
We describe how to use the pre-trained model to transcribe a sound file or multiple sound files in the following.
Install kaldifeat
kaldifeat is used to extract features for a single sound file or multiple sound files at the same time.
Please refer to https://github.com/csukuangfj/kaldifeat for installation.
Download the pre-trained model
The following commands describe how to download the pre-trained model:
$ cd egs/aishell/ASR
$ mkdir tmp
$ cd tmp
$ git lfs install
$ git clone https://huggingface.co/pkufool/icefall_asr_aishell_conformer_ctc
Caution
You have to use git lfs to download the pre-trained model.
Caution
In order to use this pre-trained model, your k2 version has to be v1.7 or later.
After downloading, you will have the following files:
$ cd egs/aishell/ASR
$ tree tmp
tmp/
`-- icefall_asr_aishell_conformer_ctc
|-- README.md
|-- data
| `-- lang_char
| |-- HLG.pt
| |-- tokens.txt
| `-- words.txt
|-- exp
| `-- pretrained.pt
`-- test_waves
|-- BAC009S0764W0121.wav
|-- BAC009S0764W0122.wav
|-- BAC009S0764W0123.wav
`-- trans.txt
5 directories, 9 files
File descriptions:
data/lang_char/HLG.ptIt is the decoding graph.
data/lang_char/tokens.txtIt contains tokens and their IDs. Provided only for convenience so that you can look up the SOS/EOS ID easily.
data/lang_char/words.txtIt contains words and their IDs.
exp/pretrained.ptIt contains pre-trained model parameters, obtained by averaging checkpoints from
epoch-25.pttoepoch-84.pt. Note: We have removed optimizerstate_dictto reduce file size.
test_waves/*.wavIt contains some test sound files from Aishell
testdataset.
test_waves/trans.txtIt contains the reference transcripts for the sound files in test_waves/.
The information of the test sound files is listed below:
$ soxi tmp/icefall_asr_aishell_conformer_ctc/test_waves/*.wav
Input File : 'tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav'
Channels : 1
Sample Rate : 16000
Precision : 16-bit
Duration : 00:00:04.20 = 67263 samples ~ 315.295 CDDA sectors
File Size : 135k
Bit Rate : 256k
Sample Encoding: 16-bit Signed Integer PCM
Input File : 'tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav'
Channels : 1
Sample Rate : 16000
Precision : 16-bit
Duration : 00:00:04.12 = 65840 samples ~ 308.625 CDDA sectors
File Size : 132k
Bit Rate : 256k
Sample Encoding: 16-bit Signed Integer PCM
Input File : 'tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav'
Channels : 1
Sample Rate : 16000
Precision : 16-bit
Duration : 00:00:04.00 = 64000 samples ~ 300 CDDA sectors
File Size : 128k
Bit Rate : 256k
Sample Encoding: 16-bit Signed Integer PCM
Total Duration of 3 files: 00:00:12.32
Usage
$ cd egs/aishell/ASR
$ ./conformer_ctc/pretrained.py --help
displays the help information.
It supports three decoding methods:
CTC decoding
HLG decoding
HLG + attention decoder rescoring
CTC decoding
CTC decoding only uses the ctc topology for decoding without a lexicon and language model
The command to run CTC decoding is:
$ cd egs/aishell/ASR
$ ./conformer_ctc/pretrained.py \
--checkpoint ./tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt \
--tokens-file ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/tokens.txt \
--method ctc-decoding \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav
The output is given below:
2021-11-18 07:53:41,707 INFO [pretrained.py:229] {'sample_rate': 16000, 'subsampling_factor': 4, 'feature_dim': 80, 'nhead': 4, 'attention_dim': 512, 'num_decoder_layers': 6, 'vgg_frontend': False, 'use_feat_batchnorm': True, 'search_beam': 20, 'output_beam': 8, 'min_active_states': 30, 'max_active_states': 10000, 'use_double_scores': True, 'env_info': {'k2-version': '1.9', 'k2-build-type': 'Release', 'k2-with-cuda': True, 'k2-git-sha1': 'f2fd997f752ed11bbef4c306652c433e83f9cf12', 'k2-git-date': 'Sun Sep 19 09:41:46 2021', 'lhotse-version': '0.11.0.dev+git.33cfe45.clean', 'torch-cuda-available': True, 'torch-cuda-version': '10.1', 'python-version': '3.8', 'icefall-git-branch': 'aishell', 'icefall-git-sha1': 'd57a873-dirty', 'icefall-git-date': 'Wed Nov 17 19:53:25 2021', 'icefall-path': '/ceph-hw/kangwei/code/icefall_aishell3', 'k2-path': '/ceph-hw/kangwei/code/k2_release/k2/k2/python/k2/__init__.py', 'lhotse-path': '/ceph-hw/kangwei/code/lhotse/lhotse/__init__.py'}, 'checkpoint': './tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt', 'tokens_file': './tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/tokens.txt', 'words_file': None, 'HLG': None, 'method': 'ctc-decoding', 'num_paths': 100, 'ngram_lm_scale': 0.3, 'attention_decoder_scale': 0.9, 'nbest_scale': 0.5, 'sos_id': 1, 'eos_id': 1, 'num_classes': 4336, 'sound_files': ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']}
2021-11-18 07:53:41,708 INFO [pretrained.py:240] device: cuda:0
2021-11-18 07:53:41,708 INFO [pretrained.py:242] Creating model
2021-11-18 07:53:51,131 INFO [pretrained.py:259] Constructing Fbank computer
2021-11-18 07:53:51,134 INFO [pretrained.py:269] Reading sound files: ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']
2021-11-18 07:53:51,138 INFO [pretrained.py:275] Decoding started
2021-11-18 07:53:51,241 INFO [pretrained.py:293] Use CTC decoding
2021-11-18 07:53:51,704 INFO [pretrained.py:369]
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav:
甚 至 出 现 交 易 几 乎 停 止 的 情 况
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav:
一 二 线 城 市 虽 然 也 处 于 调 整 中
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav:
但 因 为 聚 集 了 过 多 公 共 资 源
2021-11-18 07:53:51,704 INFO [pretrained.py:371] Decoding Done
HLG decoding
HLG decoding uses the best path of the decoding lattice as the decoding result.
The command to run HLG decoding is:
$ cd egs/aishell/ASR
$ ./conformer_ctc/pretrained.py \
--checkpoint ./tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt \
--words-file ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/words.txt \
--HLG ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt \
--method 1best \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav
The output is given below:
2021-11-18 07:37:38,683 INFO [pretrained.py:229] {'sample_rate': 16000, 'subsampling_factor': 4, 'feature_dim': 80, 'nhead': 4, 'attention_dim': 512, 'num_decoder_layers': 6, 'vgg_frontend': False, 'use_feat_batchnorm': True, 'search_beam': 20, 'output_beam': 8, 'min_active_states': 30, 'max_active_states': 10000, 'use_double_scores': True, 'env_info': {'k2-version': '1.9', 'k2-build-type': 'Release', 'k2-with-cuda': True, 'k2-git-sha1': 'f2fd997f752ed11bbef4c306652c433e83f9cf12', 'k2-git-date': 'Sun Sep 19 09:41:46 2021', 'lhotse-version': '0.11.0.dev+git.33cfe45.clean', 'torch-cuda-available': True, 'torch-cuda-version': '10.1', 'python-version': '3.8', 'icefall-git-branch': 'aishell', 'icefall-git-sha1': 'd57a873-clean', 'icefall-git-date': 'Wed Nov 17 19:53:25 2021', 'icefall-path': '/ceph-hw/kangwei/code/icefall_aishell3', 'k2-path': '/ceph-hw/kangwei/code/k2_release/k2/k2/python/k2/__init__.py', 'lhotse-path': '/ceph-hw/kangwei/code/lhotse/lhotse/__init__.py'}, 'checkpoint': './tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt', 'tokens_file': None, 'words_file': './tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/words.txt', 'HLG': './tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt', 'method': '1best', 'num_paths': 100, 'ngram_lm_scale': 0.3, 'attention_decoder_scale': 0.9, 'nbest_scale': 0.5, 'sos_id': 1, 'eos_id': 1, 'num_classes': 4336, 'sound_files': ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']}
2021-11-18 07:37:38,684 INFO [pretrained.py:240] device: cuda:0
2021-11-18 07:37:38,684 INFO [pretrained.py:242] Creating model
2021-11-18 07:37:47,651 INFO [pretrained.py:259] Constructing Fbank computer
2021-11-18 07:37:47,654 INFO [pretrained.py:269] Reading sound files: ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']
2021-11-18 07:37:47,659 INFO [pretrained.py:275] Decoding started
2021-11-18 07:37:47,752 INFO [pretrained.py:321] Loading HLG from ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt
2021-11-18 07:37:51,887 INFO [pretrained.py:340] Use HLG decoding
2021-11-18 07:37:52,102 INFO [pretrained.py:370]
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav:
甚至 出现 交易 几乎 停止 的 情况
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav:
一二 线 城市 虽然 也 处于 调整 中
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav:
但 因为 聚集 了 过多 公共 资源
2021-11-18 07:37:52,102 INFO [pretrained.py:372] Decoding Done
HLG decoding + attention decoder rescoring
It extracts n paths from the lattice, recores the extracted paths with an attention decoder. The path with the highest score is the decoding result.
The command to run HLG decoding + attention decoder rescoring is:
$ cd egs/aishell/ASR
$ ./conformer_ctc/pretrained.py \
--checkpoint ./tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt \
--words-file ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/words.txt \
--HLG ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt \
--method attention-decoder \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav \
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav
The output is below:
2021-11-18 07:42:05,965 INFO [pretrained.py:229] {'sample_rate': 16000, 'subsampling_factor': 4, 'feature_dim': 80, 'nhead': 4, 'attention_dim': 512, 'num_decoder_layers': 6, 'vgg_frontend': False, 'use_feat_batchnorm': True, 'search_beam': 20, 'output_beam': 8, 'min_active_states': 30, 'max_active_states': 10000, 'use_double_scores': True, 'env_info': {'k2-version': '1.9', 'k2-build-type': 'Release', 'k2-with-cuda': True, 'k2-git-sha1': 'f2fd997f752ed11bbef4c306652c433e83f9cf12', 'k2-git-date': 'Sun Sep 19 09:41:46 2021', 'lhotse-version': '0.11.0.dev+git.33cfe45.clean', 'torch-cuda-available': True, 'torch-cuda-version': '10.1', 'python-version': '3.8', 'icefall-git-branch': 'aishell', 'icefall-git-sha1': 'd57a873-dirty', 'icefall-git-date': 'Wed Nov 17 19:53:25 2021', 'icefall-path': '/ceph-hw/kangwei/code/icefall_aishell3', 'k2-path': '/ceph-hw/kangwei/code/k2_release/k2/k2/python/k2/__init__.py', 'lhotse-path': '/ceph-hw/kangwei/code/lhotse/lhotse/__init__.py'}, 'checkpoint': './tmp/icefall_asr_aishell_conformer_ctc/exp/pretrained.pt', 'tokens_file': None, 'words_file': './tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/words.txt', 'HLG': './tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt', 'method': 'attention-decoder', 'num_paths': 100, 'ngram_lm_scale': 0.3, 'attention_decoder_scale': 0.9, 'nbest_scale': 0.5, 'sos_id': 1, 'eos_id': 1, 'num_classes': 4336, 'sound_files': ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']}
2021-11-18 07:42:05,966 INFO [pretrained.py:240] device: cuda:0
2021-11-18 07:42:05,966 INFO [pretrained.py:242] Creating model
2021-11-18 07:42:16,821 INFO [pretrained.py:259] Constructing Fbank computer
2021-11-18 07:42:16,822 INFO [pretrained.py:269] Reading sound files: ['./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav', './tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav']
2021-11-18 07:42:16,826 INFO [pretrained.py:275] Decoding started
2021-11-18 07:42:16,916 INFO [pretrained.py:321] Loading HLG from ./tmp/icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt
2021-11-18 07:42:21,115 INFO [pretrained.py:345] Use HLG + attention decoder rescoring
2021-11-18 07:42:21,888 INFO [pretrained.py:370]
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav:
甚至 出现 交易 几乎 停止 的 情况
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav:
一二 线 城市 虽然 也 处于 调整 中
./tmp/icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav:
但 因为 聚集 了 过多 公共 资源
2021-11-18 07:42:21,889 INFO [pretrained.py:372] Decoding Done
Colab notebook
We do provide a colab notebook for this recipe showing how to use a pre-trained model.
![]()
Hint
Due to limited memory provided by Colab, you have to upgrade to Colab Pro to
run HLG decoding + attention decoder rescoring.
Otherwise, you can only run HLG decoding with Colab.
Congratulations! You have finished the aishell ASR recipe with
conformer CTC models in icefall.
If you want to deploy your trained model in C++, please read the following section.
Deployment with C++
This section describes how to deploy the pre-trained model in C++, without Python dependencies.
Hint
At present, it does NOT support streaming decoding.
First, let us compile k2 from source:
$ cd $HOME
$ git clone https://github.com/k2-fsa/k2
$ cd k2
$ git checkout v2.0-pre
Caution
You have to switch to the branch v2.0-pre!
$ mkdir build-release
$ cd build-release
$ cmake -DCMAKE_BUILD_TYPE=Release ..
$ make -j hlg_decode
# You will find four binaries in `./bin`, i.e. ./bin/hlg_decode,
Now you are ready to go!
Assume you have run:
$ cd k2/build-release $ ln -s /path/to/icefall-asr-aishell-conformer-ctc ./
To view the usage of ./bin/hlg_decode, run:
$ ./bin/hlg_decode
It will show you the following message:
Please provide --nn_model
This file implements decoding with an HLG decoding graph.
Usage:
./bin/hlg_decode \
--use_gpu true \
--nn_model <path to torch scripted pt file> \
--hlg <path to HLG.pt> \
--word_table <path to words.txt> \
<path to foo.wav> \
<path to bar.wav> \
<more waves if any>
To see all possible options, use
./bin/hlg_decode --help
Caution:
- Only sound files (*.wav) with single channel are supported.
- It assumes the model is conformer_ctc/transformer.py from icefall.
If you use a different model, you have to change the code
related to `model.forward` in this file.
HLG decoding
./bin/hlg_decode \
--use_gpu true \
--nn_model icefall_asr_aishell_conformer_ctc/exp/cpu_jit.pt \
--hlg icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt \
--word_table icefall_asr_aishell_conformer_ctc/data/lang_char/words.txt \
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav \
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav \
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav
The output is:
2021-11-18 14:48:20.89 [I] k2/torch/bin/hlg_decode.cu:115:int main(int, char**) Device: cpu
2021-11-18 14:48:20.89 [I] k2/torch/bin/hlg_decode.cu:124:int main(int, char**) Load wave files
2021-11-18 14:48:20.97 [I] k2/torch/bin/hlg_decode.cu:131:int main(int, char**) Build Fbank computer
2021-11-18 14:48:20.98 [I] k2/torch/bin/hlg_decode.cu:142:int main(int, char**) Compute features
2021-11-18 14:48:20.115 [I] k2/torch/bin/hlg_decode.cu:150:int main(int, char**) Load neural network model
2021-11-18 14:48:20.693 [I] k2/torch/bin/hlg_decode.cu:165:int main(int, char**) Compute nnet_output
2021-11-18 14:48:23.182 [I] k2/torch/bin/hlg_decode.cu:180:int main(int, char**) Load icefall_asr_aishell_conformer_ctc/data/lang_char/HLG.pt
2021-11-18 14:48:33.489 [I] k2/torch/bin/hlg_decode.cu:185:int main(int, char**) Decoding
2021-11-18 14:48:45.217 [I] k2/torch/bin/hlg_decode.cu:216:int main(int, char**)
Decoding result:
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0121.wav
甚至 出现 交易 几乎 停止 的 情况
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0122.wav
一二 线 城市 虽然 也 处于 调整 中
icefall_asr_aishell_conformer_ctc/test_waves/BAC009S0764W0123.wav
但 因为 聚集 了 过多 公共 资源
There is a Colab notebook showing you how to run a torch scripted model in C++.
Please see ![]()