If you have pre-downloaded the Aishell
dataset and the musan dataset, say,
they are saved in /tmp/aishell and /tmp/musan, you can modify
the dl_dir variable in ./prepare.sh to point to /tmp so that
./prepare.sh won’t re-download them.
Hint
A 3-gram language model will be downloaded from huggingface, we assume you have
installed and initialized git-lfs. If not, you could install git-lfs by
$sudoapt-getinstallgit-lfs
$git-lfsinstall
If you don’t have the sudo permission, you could download the
git-lfs binary here, then add it to you PATH.
Note
All generated files by ./prepare.sh, e.g., features, lexicon, etc,
are saved in ./data directory.
shows you the training options that can be passed from the commandline.
The following options are used quite often:
--num-epochs
It is the number of epochs to train. For instance,
./tdnn_lstm_ctc/train.py--num-epochs30 trains for 30 epochs
and generates epoch-0.pt, epoch-1.pt, …, epoch-29.pt
in the folder ./tdnn_lstm_ctc/exp.
--start-epoch
It’s used to resume training.
./tdnn_lstm_ctc/train.py--start-epoch10 loads the
checkpoint ./tdnn_lstm_ctc/exp/epoch-9.pt and starts
training from epoch 10, based on the state from epoch 9.
--world-size
It is used for multi-GPU single-machine DDP training.
If it is 1, then no DDP training is used.
If it is 2, then GPU 0 and GPU 1 are used for DDP training.
The following shows some use cases with it.
Use case 1: You have 4 GPUs, but you only want to use GPU 0 and
GPU 2 for training. You can do the following:
Only multi-GPU single-machine DDP training is implemented at present.
Multi-GPU multi-machine DDP training will be added later.
--max-duration
It specifies the number of seconds over all utterances in a
batch, before padding.
If you encounter CUDA OOM, please reduce it. For instance, if
your are using V100 NVIDIA GPU, we recommend you to set it to 2000.
Hint
Due to padding, the number of seconds of all utterances in a
batch will usually be larger than --max-duration.
A larger value for --max-duration may cause OOM during training,
while a smaller value may increase the training time. You have to
tune it.
There are some training options, e.g., weight decay,
number of warmup steps, results dir, etc,
that are not passed from the commandline.
They are pre-configured by the function get_params() in
tdnn_lstm_ctc/train.py
You don’t need to change these pre-configured parameters. If you really need to change
them, please modify ./tdnn_lstm_ctc/train.py directly.
Caution
The training set is perturbed by speed with two factors: 0.9 and 1.1.
Each epoch actually processes 3x150==450 hours of data.
Training logs and checkpoints are saved in tdnn_lstm_ctc/exp.
You will find the following files in that directory:
epoch-0.pt, epoch-1.pt, …
These are checkpoint files, containing model state_dict and optimizer state_dict.
To resume training from some checkpoint, say epoch-10.pt, you can use:
$./tdnn_lstm_ctc/train.py--start-epoch11
tensorboard/
This folder contains TensorBoard logs. Training loss, validation loss, learning
rate, etc, are recorded in these logs. You can visualize them by:
$cdtdnn_lstm_ctc/exp/tensorboard
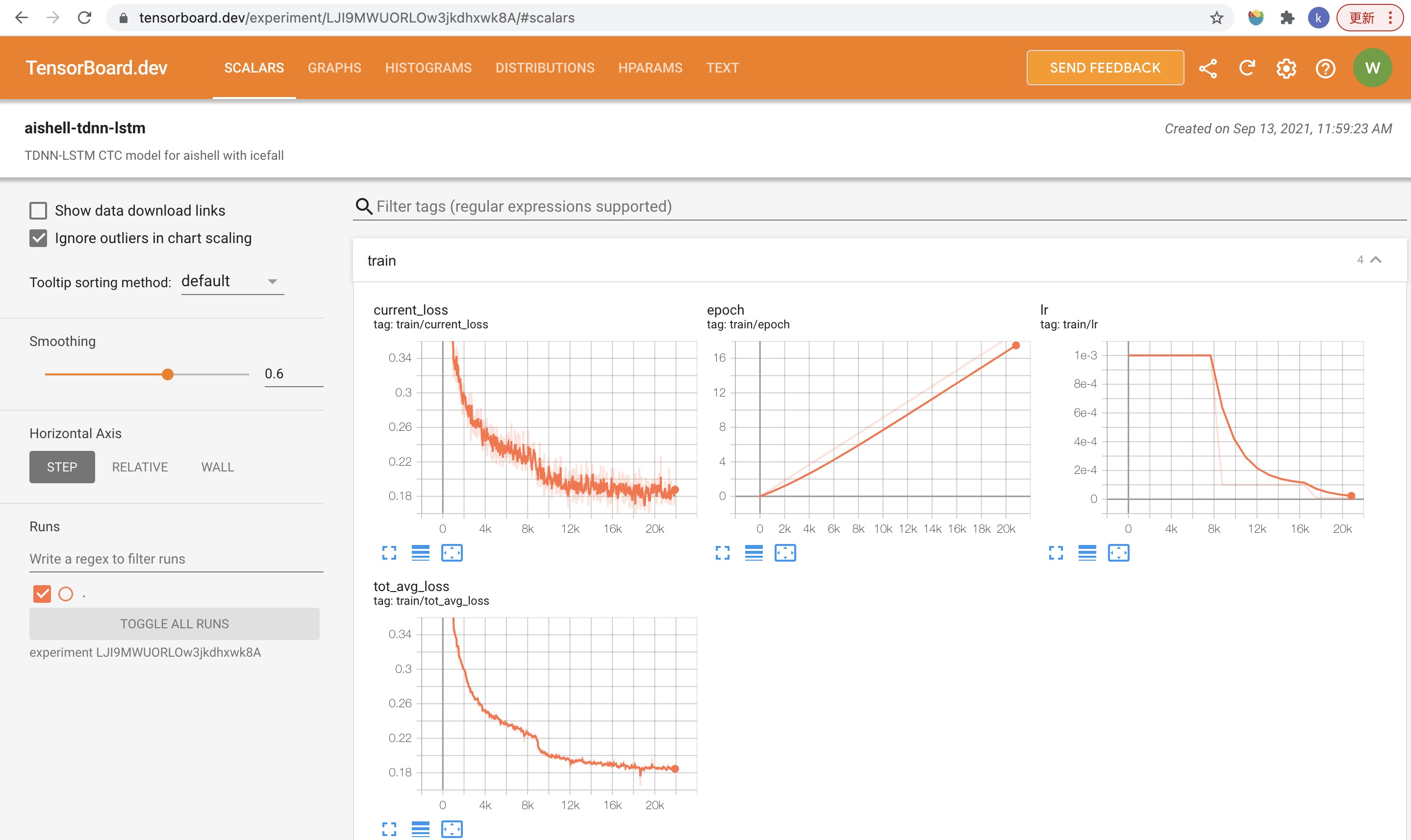
$tensorboarddevupload--logdir.--description"TDNN-LSTM CTC training for Aishell with icefall"
It will print something like below:
TensorFlowinstallationnotfound-runningwithreducedfeatureset.Uploadstartedandwillcontinuereadinganynewdataasit's added to the logdir.Tostopuploading,pressCtrl-C.Newexperimentcreated.ViewyourTensorBoardat:https://tensorboard.dev/experiment/LJI9MWUORLOw3jkdhxwk8A/[2021-09-13T11:59:23]Startedscanninglogdir.[2021-09-13T11:59:24]Totaluploaded:4454scalars,0tensors,0binaryobjectsListeningfornewdatainlogdir...
Note there is a URL in the above output, click it and you will see
the following screenshot:
It contains tokens and their IDs.
Provided only for convenience so that you can look up the SOS/EOS ID easily.
data/lang_phone/words.txt
It contains words and their IDs.
exp/pretrained.pt
It contains pre-trained model parameters, obtained by averaging
checkpoints from epoch-18.pt to epoch-40.pt.
Note: We have removed optimizer state_dict to reduce file size.
test_waves/*.wav
It contains some test sound files from Aishell test dataset.
test_waves/trans.txt
It contains the reference transcripts for the sound files in test_waves/.
The information of the test sound files is listed below: