Conv-Emformer-transducer-based Models
Hint
See Installation to install sherpa-ncnn before you read this section.
marcoyang/sherpa-ncnn-conv-emformer-transducer-small-2023-01-09 (English)
This model is a small version of conv-emformer-transducer trained in icefall.
It only has 8.8 million parameters and can be deployed on embedded devices
for real-time speech recognition. You can find the models in fp16 and int8 format
at https://huggingface.co/marcoyang/sherpa-ncnn-conv-emformer-transducer-small-2023-01-09.
This model is trained using LibriSpeech and thus it supports only English.
In the following, we show you how to download it and deploy it with sherpa-ncnn on an embedded device, whose CPU is RV1126 (Quad core ARM Cortex-A7)
Please use the following commands to download it.
cd /path/to/sherpa-ncnn
wget https://github.com/k2-fsa/sherpa-ncnn/releases/download/models/sherpa-ncnn-conv-emformer-transducer-small-2023-01-09.tar.bz2
tar xvf sherpa-ncnn-conv-emformer-transducer-small-2023-01-09.tar.bz2
Note
See Embedded Linux (arm) for how to compile sherpa-ncnn for a 32-bit ARM platform. In the following, we test the pre-trained model on an embedded device, whose CPU is RV1126 (Quad core ARM Cortex-A7).
Decode a single wave file with ./build/bin/sherpa-ncnn
Hint
It supports decoding only wave files with a single channel and the sampling rate should be 16 kHz.
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/joiner_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/test_wavs/1089-134686-0001.wav \
The outputs are shown below. The CPU used for decoding is RV1126 (Quad core ARM Cortex-A7).

Note
The default option uses 4 threads and greedy_search for decoding.
Note
Please use ./build/bin/Release/sherpa-ncnn.exe for Windows.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
Decode a single wave file with ./build/bin/sherpa-ncnn (with int8 quantization)
Note
We also support int8 quantization to compresss the model and speed up inference. Currently, only encoder and joiner are quantized.
To decode the int8-quantized model, use the following command:
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/encoder_jit_trace-pnnx.ncnn.int8.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/encoder_jit_trace-pnnx.ncnn.int8.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/joiner_jit_trace-pnnx.ncnn.int8.param \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/joiner_jit_trace-pnnx.ncnn.int8.bin \
./sherpa-ncnn-conv-emformer-transducer-small-2023-01-09/test_wavs/1089-134686-0001.wav \
The outputs are shown below. The CPU used for decoding is RV1126 (Quad core ARM Cortex-A7).
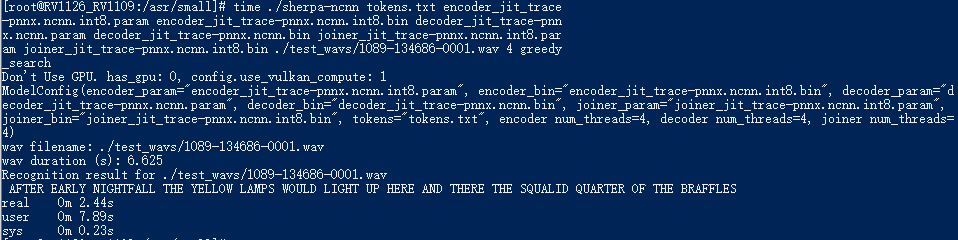
Compared to the original model in fp16 format,
the decoding speed is significantly improved. The decoding time is changed from
3.26 s to 2.44 s.
Note
When the model’s weights are quantized to float16, it is converted
to float32 during computation.
When the model’s weights are quantized to int8, it is using int8
during computation.
Hint
Even if we use only 1 thread for the int8 model, the resulting real
time factor (RTF) is still less than 1.
csukuangfj/sherpa-ncnn-conv-emformer-transducer-2022-12-06 (Chinese + English)
This model is converted from https://huggingface.co/ptrnull/icefall-asr-conv-emformer-transducer-stateless2-zh, which supports both Chinese and English.
Hint
If you want to train your own model that is able to support both Chinese and English, see our training code:
You can also try the pre-trained models in your browser without installing anything by visiting:
In the following, we describe how to download and use it with sherpa-ncnn.
Please use the following commands to download it.
cd /path/to/sherpa-ncnn
wget https://github.com/k2-fsa/sherpa-ncnn/releases/download/models/sherpa-ncnn-conv-emformer-transducer-2022-12-06.tar.bz2
tar xvf sherpa-ncnn-conv-emformer-transducer-2022-12-06.tar.bz2
Decode a single wave file with ./build/bin/sherpa-ncnn
Hint
It supports decoding only wave files with a single channel and the sampling rate should be 16 kHz.
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/test_wavs/0.wav \
Note
Please use ./build/bin/Release/sherpa-ncnn.exe for Windows.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
Real-time speech recognition from a microphone with build/bin/sherpa-ncnn-microphone
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn-microphone \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-06/joiner_jit_trace-pnnx.ncnn.bin
Note
Please use ./build/bin/Release/sherpa-ncnn-microphone.exe for Windows.
It will print something like below:
Number of threads: 4
num devices: 4
Use default device: 2
Name: MacBook Pro Microphone
Max input channels: 1
Started
Speak and it will show you the recognition result in real-time.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
csukuangfj/sherpa-ncnn-conv-emformer-transducer-2022-12-08 (Chinese)
Hint
This is a very small model that can be run in real-time on embedded sytems.
This model is trained using WenetSpeech dataset and it supports only Chinese.
In the following, we describe how to download and use it with sherpa-ncnn.
Please use the following commands to download it.
cd /path/to/sherpa-ncnn
wget https://github.com/k2-fsa/sherpa-ncnn/releases/download/models/sherpa-ncnn-conv-emformer-transducer-2022-12-08.tar.bz2
tar xvf sherpa-ncnn-conv-emformer-transducer-2022-12-08.tar.bz2
Decode a single wave file with ./build/bin/sherpa-ncnn
Hint
It supports decoding only wave files with a single channel and the sampling rate should be 16 kHz.
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/joiner_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/test_wavs/0.wav
Note
Please use ./build/bin/Release/sherpa-ncnn.exe for Windows.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
Real-time speech recognition from a microphone with build/bin/sherpa-ncnn-microphone
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn-microphone \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-08/joiner_jit_trace-pnnx.ncnn.bin
Note
Please use ./build/bin/Release/sherpa-ncnn-microphone.exe for Windows.
It will print something like below:
Number of threads: 4
num devices: 4
Use default device: 2
Name: MacBook Pro Microphone
Max input channels: 1
Started
Speak and it will show you the recognition result in real-time.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
csukuangfj/sherpa-ncnn-conv-emformer-transducer-2022-12-04 (English)
This model is trained using GigaSpeech and LibriSpeech. It supports only English.
In the following, we describe how to download and use it with sherpa-ncnn.
Please use the following commands to download it.
cd /path/to/sherpa-ncnn
wget https://github.com/k2-fsa/sherpa-ncnn/releases/download/models/sherpa-ncnn-conv-emformer-transducer-2022-12-04.tar.bz2
tar xvf sherpa-ncnn-conv-emformer-transducer-2022-12-04.tar.bz2
Decode a single wave file with ./build/bin/sherpa-ncnn
Hint
It supports decoding only wave files with a single channel and the sampling rate should be 16 kHz.
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/joiner_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/joiner_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/test_wavs/1089-134686-0001.wav
Note
Please use ./build/bin/Release/sherpa-ncnn.exe for Windows.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.
Real-time speech recognition from a microphone with build/bin/sherpa-ncnn-microphone
cd /path/to/sherpa-ncnn
./build/bin/sherpa-ncnn-microphone \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/tokens.txt \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/encoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/encoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/decoder_jit_trace-pnnx.ncnn.param \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/decoder_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/joiner_jit_trace-pnnx.ncnn.bin \
./sherpa-ncnn-conv-emformer-transducer-2022-12-04/joiner_jit_trace-pnnx.ncnn.param
Note
Please use ./build/bin/Release/sherpa-ncnn-microphone.exe for Windows.
It will print something like below:
Number of threads: 4
num devices: 4
Use default device: 2
Name: MacBook Pro Microphone
Max input channels: 1
Started
Speak and it will show you the recognition result in real-time.
Caution
If you use Windows and get encoding issues, please run:
CHCP 65001
in your commandline.