Hotwords (Contextual biasing)
In this section, we describe how we implement the hotwords (aka contextual biasing) feature with an Aho-corasick automaton and how to use it in sherpa-onnx.
Caution
Only transducer models support hotwords in sherpa-onnx. That is, only models from Offline transducer models and Online transducer models support hotwords.
All other models don’t support hotwords.
Also, you have to change the decoding method to modified_beam_search
to use hotwords. The default decoding method greedy_search does not
support hotwords.
What are hotwords
Current ASR systems work very well for general cases, but they sometimes fail to
recognize special words/phrases (aka hotwords) like rare words, personalized
information etc. Usually, those words/phrases will be recognized as the words/phrases
that pronounce similar to them (for example, recognize LOUIS FOURTEEN as LEWIS FOURTEEN).
So we have to provide some kind of contexts information (for example, the LOUIS FOURTEEN)
to the ASR systems to boost those words/phrases. Normally, we call this kind of
boosting task contextual biasing (aka hotwords recognition).
How do we implement it with an Aho-corasick
We first construct an Aho-corasick automaton on those given hotwords (after tokenizing into tokens). See https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm for the construction details of Aho-corasick.
The figure below is the aho-corasick on “HE/SHE/SHELL/HIS/THIS” with hotwords-score==1.
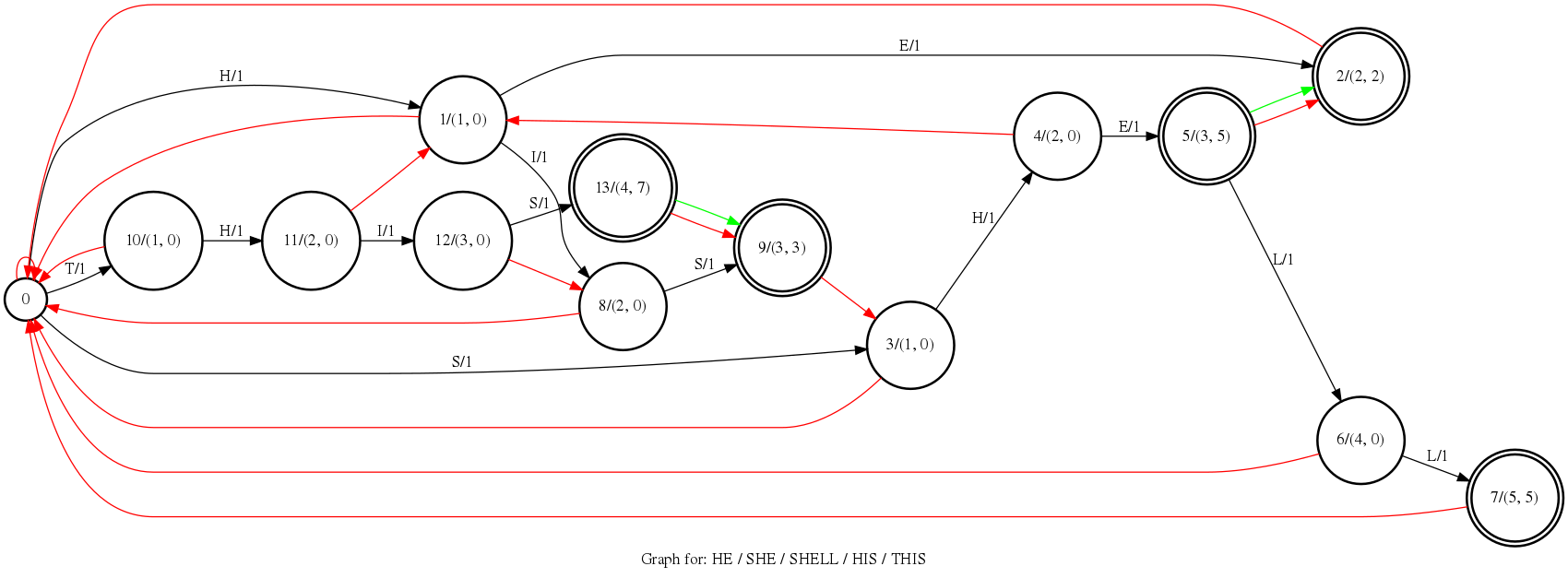
Fig. 128 The Aho-corasick for “HE/SHE/SHELL/HIS/THIS”
The black arrows in the graph are the goto arcs, the red arrows are the
failure arcs, the green arrows are the output arcs. On each goto arc, there
are token and boosting score (Note: we will boost the path when any partial
sequence is matched, if the path finally fails to full match any hotwords, the boosted
score will be canceled). Currentlly, the boosting score distributes on the arcs
evenly along the path. On each state, there are two scores, the first one is the
node score (mainly used to cancel score) the second one is output score, the output
score is the total scores of the full matched hotwords of this state.
The following are several matching examples of the graph above.
Note
For simplicity, we assume that the system emits a token each frame.
Hint
We have an extra finalize step to force the graph state to go back to
the root state.
The path is “SHELF”
Frame |
Boost score |
Total boost score |
Graph state |
Matched hotwords |
init |
0 |
0 |
0 |
|
1 |
1 |
1 |
3 |
|
2 |
1 |
2 |
4 |
|
3 |
1 + 5 |
8 |
5 |
HE, SHE |
4 |
1 |
9 |
6 |
|
5 |
-4 |
5 |
0 |
|
finalize |
0 |
5 |
0 |
At frame 3 we reach state 5 and match HE, SHE, so we get a boosting
score 1 + 5, the score 1 here because the SHEL still might be the prefix
of other hotwords.
At frame 5 F can not match any tokens and fail back to root, so we cancel
the score for SHEL which is 4 (the node score of state 6).
The path is “HI”
Frame |
Boost score |
Total boost score |
Graph state |
Matched hotwords |
init |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
|
2 |
1 |
2 |
8 |
|
finalize |
-2 |
0 |
0 |
H and I all match the tokens in the graph, unfortunately, we have to go
back to root state when finishing matching a path, so we cancel the boosting score
of HI which is 2 (the node score of state 8).
The path is “THE”
Frame |
Boost score |
Total boost score |
Graph state |
Matched hotwords |
init |
0 |
0 |
0 |
|
1 |
1 |
1 |
10 |
|
2 |
1 |
2 |
11 |
|
3 |
0 + 2 |
4 |
2 |
HE |
finalize |
-2 |
3 |
0 |
At frame 3 we jump from state 11 to state 2 and get a boosting score
of 0 + 2, 0 because the node score of state 2 is the same as state 11
so we don’t get score by partial match (the prefix of state 11 is TH has
the same length of the prefix of state 2 which is HE), but we do get the
output score (at state 2 it outputs HE).
Note
We implement the hotwords feature during inference time, you don’t have to re-train the models to use this feature.
How to use hotwords in sherpa-onnx
Caution
Currentlly, the hotwords feature is only supported in the
modified_beam_search decoding method of the transducer models
(both streaming and non-streaming).
The use of the hotwords is no different for streaming and non-streaming models, and in fact it is even no different for all the API supported by sherpa onnx. We add FOUR extra arguments for hotwords:
hotwords-fileThe file path of the hotwords, one hotwords per line. They could be Chinese words, English words or both according to the modeling units used to train the model. Here are some examples:
For Chinese models trained on
cjkcharit looks like:语音识别 深度学习For English like language models trained on
bpeit looks like:SPEECH RECOGNITION DEEP LEARNINGFor multilingual models trained on
cjkchar+bpe(Chinese + English) it looks like:SPEECH 识别 SPEECH RECOGNITION 深度学习You can also specify the boosting score for each hotword, the score should follow the predefined character :, for example:
语音识别 :3.5 深度学习 :2.0It means, hotword 语音识别 will have a boosting score of 3.5, hotword 深度学习 will have a boosting score of 2.0. For those hotwords that don’t have specific scores, they will use the global score provided by hotword-score below.
Caution
The specific score MUST BE the last item of each hotword (i.e You shouldn’t break the hotword into two parts by the score). SPEECH :2.0 识别 # This is invalid
hotwords-scoreThe boosting score for each matched token.
Note
We match the hotwords at token level, so the
hotwords-scoreis applied at token level.
modeling-unitThe modeling unit of the used model, currently support cjkchar (for Chinese), bpe (for English like languages) and cjkchar+bpe (for multilingual models). We need this modeling-unit to select tokenizer to encode words/phrases into tokens, so do provide correct modeling-unit according to your model.
bpe-vocabThe bpe vocabulary generated by sentencepiece toolkit, it also can be exported from bpe.model (see script/export_bpe_vocab.py for details). This vocabulary is used to tokenize words/phrases into bpe units. It is only used when modeling-unit is bpe or cjkchar+bpe.
Hint
We need bpe.vocab rather than bpe.model, because we don’t introduce sentencepiece c++ codebase into sherpa-onnx (which has a depandancy issue of protobuf) , we implement a simple sentencepiece encoder and decoder which takes bpe.vocab as input.
The main difference of using hotwords feature is about the modeling units. The following shows how to use it for different modeling units.
Hint
You can use any transducer models here https://k2-fsa.github.io/sherpa/onnx/pretrained_models/index.html, we just choose three of them randomly for the following examples.
Note
In the following example, we use a non-streaming model, if you are using a
streaming model, you should use sherpa-onnx. sherpa-onnx-alsa,
sherpa-onnx-microphone, sherpa-onnx-microphone-offline,
sherpa-onnx-online-websocket-server and sherpa-onnx-offline-websocket-server
all support hotwords.
Modeling unit is bpe
Download the model
cd /path/to/sherpa-onnx
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-zipformer-en-2023-04-01.tar.bz2
tar xvf sherpa-onnx-zipformer-en-2023-04-01.tar.bz2
rm sherpa-onnx-zipformer-en-2023-04-01.tar.bz2
ln -s sherpa-onnx-zipformer-en-2023-04-01 exp
Export bpe.vocab if you can’t find bpe.vocab in the model directory.
python script/export_bpe_vocab.py --bpe-model exp/bpe.model
The hotwords_en.txt contains:
QUARTERS
FOREVER
C++ api
Decoding without hotwords
./build/bin/sherpa-onnx-offline \
--encoder=exp/encoder-epoch-99-avg-1.onnx \
--decoder=exp/decoder-epoch-99-avg-1.onnx \
--joiner=exp/joiner-epoch-99-avg-1.onnx \
--decoding-method=modified_beam_search \
--tokens=exp/tokens.txt \
exp/test_wavs/0.wav exp/test_wavs/1.wav
The output is:
/star-kw/kangwei/code/sherpa-onnx/sherpa-onnx/csrc/parse-options.cc:Read:361 ./build/bin/sherpa-onnx-offline --encoder=exp/encoder-epoch-99-avg-1.onnx --decoder=exp/decoder-epoch-99-avg-1.onnx --joiner=exp/joiner-epoch-99-avg-1.onnx --decoding-method=modified_beam_search --tokens=exp/tokens.txt exp/test_wavs/0.wav exp/test_wavs/1.wav
OfflineRecognizerConfig(feat_config=OfflineFeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OfflineModelConfig(transducer=OfflineTran$ducerModelConfig(encoder_filename="exp/encoder-epoch-99-avg-1.onnx", decoder_filename="exp/decoder-epoch-99-avg-1.onnx", joiner_filename="exp/joiner-epoch-99-$vg-1.onnx"), paraformer=OfflineParaformerModelConfig(model=""), nemo_ctc=OfflineNemoEncDecCtcModelConfig(model=""), whisper=OfflineWhisperModelConfig(encoder=$", decoder="", language="", task="transcribe"), tdnn=OfflineTdnnModelConfig(model=""), tokens="exp/tokens.txt", num_threads$2, debug=False, provider="cpu", model_type=""), lm_config=OfflineLMConfig(model="", scale=0.5), decoding_method="modified_beam_search", max_active_paths=4, ho$words_file=, hotwords_score=1.5)
Creating recognizer ...
Started
Done!
exp/test_wavs/0.wav
{"text":"ALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTER OF THE BROTHELS","timestamps":"[1.44, 1.48, 1.56, 1.72, 1.88, 1.96, 2.16, 2.28$ 2.36, 2.48, 2.60, 2.80, 3.08, 3.28, 3.40, 3.60, 3.80, 4.08, 4.24, 4.32, 4.48, 4.64, 4.84, 4.88, 5.00, 5.08, 5.32, 5.48, 5.60, 5.68, 5.84, 6.04, 6.24]","token$":["A","LL"," THE"," YE","LL","OW"," LA","M","P","S"," WOULD"," LIGHT"," UP"," HE","RE"," AND"," THERE"," THE"," S","QUA","LI","D"," ","QUA","R","TER"," OF","THE"," B","RO","TH","EL","S"]}
----
exp/test_wavs/1.wav
{"text":"IN WHICH MAN THUS PUNISHED HAD GIVEN HER A LOVELY CHILD WHOSE PLACE WAS ON THAT SAME DISHONOURED BOSOM TO CONNECT HER PARENT FOR EVER WITH THE RACE AN
D DESCENT OF MORTALS AND TO BE FINALLY A BLESSED SOUL IN HEAVEN","timestamps":"[2.44, 2.64, 2.88, 3.16, 3.28, 3.48, 3.60, 3.80, 3.96, 4.12, 4.36, 4.52, 4.72, 4
.92, 5.16, 5.44, 5.68, 6.04, 6.24, 6.48, 6.84, 7.08, 7.32, 7.56, 7.84, 8.12, 8.24, 8.32, 8.44, 8.60, 8.76, 8.88, 9.08, 9.28, 9.44, 9.56, 9.64, 9.76, 9.96, 10.0
4, 10.20, 10.40, 10.64, 10.76, 11.04, 11.20, 11.36, 11.60, 11.80, 12.00, 12.12, 12.28, 12.32, 12.52, 12.72, 12.84, 12.96, 13.04, 13.24, 13.40, 13.60, 13.76, 13
.96, 14.12, 14.24, 14.36, 14.52, 14.68, 14.76, 15.04, 15.28, 15.52, 15.76, 16.00, 16.16, 16.24, 16.32]","tokens":["IN"," WHICH"," MAN"," TH","US"," P","UN","IS
H","ED"," HAD"," GIVE","N"," HER"," A"," LOVE","LY"," CHILD"," WHO","SE"," PLACE"," WAS"," ON"," THAT"," SAME"," DIS","HO","N","OUR","ED"," BO","S","OM"," TO",
" CON","NE","C","T"," HER"," P","AR","ENT"," FOR"," E","VER"," WITH"," THE"," RA","CE"," AND"," DE","S","C","ENT"," OF"," MO","R","T","AL","S"," AND"," TO"," B
E"," FI","N","AL","LY"," A"," B","LESS","ED"," SO","UL"," IN"," HE","A","VE","N"]}
----
num threads: 2
decoding method: modified_beam_search
max active paths: 4
Elapsed seconds: 1.775 s
Real time factor (RTF): 1.775 / 23.340 = 0.076
Decoding with hotwords
./build/bin/sherpa-onnx-offline \
--encoder=exp/encoder-epoch-99-avg-1.onnx \
--decoder=exp/decoder-epoch-99-avg-1.onnx \
--joiner=exp/joiner-epoch-99-avg-1.onnx \
--decoding-method=modified_beam_search \
--tokens=exp/tokens.txt \
--modeling-unit=bpe \
--bpe-vocab=exp/bpe.vocab \
--hotwords-file=hotwords_en.txt \
--hotwords-score=2.0 \
exp/test_wavs/0.wav exp/test_wavs/1.wav
The output is:
/star-kw/kangwei/code/sherpa-onnx/sherpa-onnx/csrc/parse-options.cc:Read:361 ./build/bin/sherpa-onnx-offline --encoder=exp/encoder-epoch-99-avg-1.onnx --decoder=exp/decoder-epoch-99-avg-1.onnx --joiner=exp/joiner-epoch-99-avg-1.onnx --decoding-method=modified_beam_search --tokens=exp/tokens.txt --hotwords-file=hotwords_en.txt --hotwords-score=2.0 exp/test_wavs/0.wav exp/test_wavs/1.wav
OfflineRecognizerConfig(feat_config=OfflineFeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OfflineModelConfig(transducer=OfflineTransducerModelConfig(encoder_filename="exp/encoder-epoch-99-avg-1.onnx", decoder_filename="exp/decoder-epoch-99-avg-1.onnx", joiner_filename="exp/joiner-epoch-99-avg-1.onnx"), paraformer=OfflineParaformerModelConfig(model=""), nemo_ctc=OfflineNemoEncDecCtcModelConfig(model=""), whisper=OfflineWhisperModelConfig(encoder="
", decoder="", language="", task="transcribe"), tdnn=OfflineTdnnModelConfig(model=""), tokens="exp/tokens.txt", num_threads=2, debug=False, provider="cpu", model_type=""), lm_config=OfflineLMConfig(model="", scale=0.5), decoding_method="modified_beam_search", max_active_paths=4, hotwords_file=hotwords_en.txt, hotwords_score=2)
Creating recognizer ...
Started
Done!
exp/test_wavs/0.wav
{"text":"ALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTERS OF THE BROTHELS","timestamps":"[1.44, 1.48, 1.56, 1.72, 1.88, 1.96, 2.16, 2.28
, 2.36, 2.48, 2.60, 2.80, 3.08, 3.28, 3.40, 3.60, 3.80, 4.08, 4.24, 4.32, 4.48, 4.64, 4.84, 4.88, 5.00, 5.08, 5.12, 5.36, 5.48, 5.60, 5.68, 5.84, 6.04, 6.24]",
"tokens":["A","LL"," THE"," YE","LL","OW"," LA","M","P","S"," WOULD"," LIGHT"," UP"," HE","RE"," AND"," THERE"," THE"," S","QUA","LI","D"," ","QUA","R","TER",$
S"," OF"," THE"," B","RO","TH","EL","S"]}
----
exp/test_wavs/1.wav
{"text":"IN WHICH MAN THUS PUNISHED HAD GIVEN HER A LOVELY CHILD WHOSE PLACE WAS ON THAT SAME DISHONOURED BOSOM TO CONNECT HER PARENT FOREVER WITH THE RACE AN$
DESCENT OF MORTALS AND TO BE FINALLY A BLESSED SOUL IN HEAVEN","timestamps":"[2.44, 2.64, 2.88, 3.16, 3.28, 3.48, 3.60, 3.80, 3.96, 4.12, 4.36, 4.52, 4.72, 4$
92, 5.16, 5.44, 5.68, 6.04, 6.24, 6.48, 6.84, 7.08, 7.32, 7.56, 7.84, 8.12, 8.24, 8.32, 8.44, 8.60, 8.76, 8.88, 9.08, 9.28, 9.44, 9.56, 9.64, 9.76, 9.96, 10.0$
, 10.20, 10.40, 10.68, 10.76, 11.04, 11.20, 11.36, 11.60, 11.80, 12.00, 12.12, 12.28, 12.32, 12.52, 12.72, 12.84, 12.96, 13.04, 13.24, 13.40, 13.60, 13.76, 13$
96, 14.12, 14.24, 14.36, 14.52, 14.68, 14.76, 15.04, 15.28, 15.52, 15.76, 16.00, 16.16, 16.24, 16.32]","tokens":["IN"," WHICH"," MAN"," TH","US"," P","UN","IS$
","ED"," HAD"," GIVE","N"," HER"," A"," LOVE","LY"," CHILD"," WHO","SE"," PLACE"," WAS"," ON"," THAT"," SAME"," DIS","HO","N","OUR","ED"," BO","S","OM"," TO",$
CON","NE","C","T"," HER"," P","AR","ENT"," FOR","E","VER"," WITH"," THE"," RA","CE"," AND"," DE","S","C","ENT"," OF"," MO","R","T","AL","S"," AND"," TO"," BE$
," FI","N","AL","LY"," A"," B","LESS","ED"," SO","UL"," IN"," HE","A","VE","N"]}
----
num threads: 2
decoding method: modified_beam_search
max active paths: 4
Elapsed seconds: 1.522 s
Real time factor (RTF): 1.522 / 23.340 = 0.065
Hint
QUARTER -> QUARTERS
FOR EVER -> FOREVER
Python api
Decoding without hotwords
python python-api-examples/offline-decode-files.py \
--encoder exp/encoder-epoch-99-avg-1.onnx \
--decoder exp/decoder-epoch-99-avg-1.onnx \
--joiner exp/joiner-epoch-99-avg-1.onnx \
--decoding modified_beam_search \
--tokens exp/tokens.txt \
exp/test_wavs/0.wav exp/test_wavs/1.wav
The output is:
Started!
Done!
exp/test_wavs/0.wav
ALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTER OF THE BROTHELS
----------
exp/test_wavs/1.wav
IN WHICH MAN THUS PUNISHED HAD GIVEN HER A LOVELY CHILD WHOSE PLACE WAS ON THAT SAME DISHONOURED BOSOM TO CONNECT HER PARENT FOR EVER WITH THE RACE AND DESCENT OF MORTALS AND TO BE FINALLY A BLESSED SOUL IN HEAVEN
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 23.340 s
Elapsed time: 2.546 s
Real time factor (RTF): 2.546/23.340 = 0.109
Decoding with hotwords
python python-api-examples/offline-decode-files.py \
--encoder exp/encoder-epoch-99-avg-1.onnx \
--decoder exp/decoder-epoch-99-avg-1.onnx \
--joiner exp/joiner-epoch-99-avg-1.onnx \
--decoding modified_beam_search \
--tokens exp/tokens.txt \
--modeling-unit bpe \
--bpe-vocab exp/bpe.vocab \
--hotwords-file hotwords_en.txt \
--hotwords-score 2.0 \
exp/test_wavs/0.wav exp/test_wavs/1.wav
The output is:
Started!
Done!
exp/test_wavs/0.wav
ALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTERS OF THE BROTHELS
----------
exp/test_wavs/1.wav
IN WHICH MAN THUS PUNISHED HAD GIVEN HER A LOVELY CHILD WHOSE PLACE WAS ON THAT SAME DISHONOURED BOSOM TO CONNECT HER PARENT FOREVER WITH THE RACE AND DESCENTOF MORTALS AND TO BE FINALLY A BLESSED SOUL IN HEAVEN
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 23.340 s
Elapsed time: 2.463 s
Real time factor (RTF): 2.463/23.340 = 0.106
Hint
QUARTER -> QUARTERS
FOR EVER -> FOREVER
Modeling unit is cjkchar
Download the model
cd /path/to/sherpa-onnx
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-conformer-zh-stateless2-2023-05-23.tar.bz2
tar xvf sherpa-onnx-conformer-zh-stateless2-2023-05-23.tar.bz2
rm sherpa-onnx-conformer-zh-stateless2-2023-05-23.tar.bz2
ln -s sherpa-onnx-conformer-zh-stateless2-2023-05-23 exp-zh
The hotwords_cn.txt contains:
文森特卡索
周望君
朱丽楠
蒋有伯
C++ api
Decoding without hotwords
./build/bin/sherpa-onnx-offline \
--encoder=exp-zh/encoder-epoch-99-avg-1.onnx \
--decoder=exp-zh/decoder-epoch-99-avg-1.onnx \
--joiner=exp-zh/joiner-epoch-99-avg-1.onnx \
--tokens=exp-zh/tokens.txt \
--decoding-method=modified_beam_search \
exp-zh/test_wavs/3.wav exp-zh/test_wavs/4.wav exp-zh/test_wavs/5.wav exp-zh/test_wavs/6.wav
The output is:
/star-kw/kangwei/code/sherpa-onnx/sherpa-onnx/csrc/parse-options.cc:Read:361 ./build/bin/sherpa-onnx-offline --encoder=exp-zh/encoder-epoch-99-avg-1.onnx --decoder=exp-zh/decoder-epoch-99-avg-1.onnx --joiner=exp-zh/joiner-epoch-99-avg-1.onnx --tokens=exp-zh/tokens.txt --decoding-method=modified_beam_search exp-zh/test_wavs/3.wav exp-zh/test_wavs/4.wav exp-zh/test_wavs/5.wav exp-zh/test_wavs/6.wav
OfflineRecognizerConfig(feat_config=OfflineFeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OfflineModelConfig(transducer=OfflineTransducerModelConfig(encoder_filename="exp-zh/encoder-epoch-99-avg-1.onnx", decoder_filename="exp-zh/decoder-epoch-99-avg-1.onnx", joiner_filename="exp-zh/joiner-$poch-99-avg-1.onnx"), paraformer=OfflineParaformerModelConfig(model=""), nemo_ctc=OfflineNemoEncDecCtcModelConfig(model=""), whisper=OfflineWhisperModelConfig$encoder="", decoder="", language="", task="transcribe"), tdnn=OfflineTdnnModelConfig(model=""), tokens="exp-zh/tokens.txt", num_threads=2, debug=False, provider="cpu", model_type=""), lm_config=OfflineLMConfig(model="", scale=0.5), decoding_method="modified_beam_search", max_active$paths=4, hotwords_file=, hotwords_score=1.5)
Creating recognizer ...
Started
Done!
exp-zh/test_wavs/3.wav
{"text":"文森特卡所是全球知名的法国性格派演员","timestamps":"[0.00, 0.16, 0.68, 1.32, 1.72, 2.08, 2.60, 2.88, 3.20, 3.52, 3.92, 4.40, 4.68, 5.12, 5.44, 6.36, $.96, 7.32]","tokens":["文","森","特","卡","所","是","全","球","知","名","的","法","国","性","格","派","演","员"]}
----
exp-zh/test_wavs/4.wav
{"text":"蒋友伯被拍到带着女儿出游","timestamps":"[0.00, 0.20, 0.88, 1.36, 1.76, 2.08, 2.28, 2.68, 2.92, 3.16, 3.44, 3.80]","tokens":["蒋","友","伯","被","拍",$
到","带","着","女","儿","出","游"]}
----
exp-zh/test_wavs/5.wav
{"text":"周望军就落实控物价","timestamps":"[0.00, 0.16, 0.88, 1.24, 1.64, 1.96, 2.76, 3.04, 3.32]","tokens":["周","望","军","就","落","实","控","物","价"]}
----
exp-zh/test_wavs/6.wav
{"text":"朱立南在上市见面会上表示","timestamps":"[0.00, 0.16, 0.80, 1.12, 1.44, 1.68, 1.92, 2.16, 2.36, 2.60, 2.84, 3.12]","tokens":["朱","立","南","在","上",$
市","见","面","会","上","表","示"]}
----
num threads: 2
decoding method: modified_beam_search
max active paths: 4
Elapsed seconds: 1.883 s
Real time factor (RTF): 1.883 / 20.328 = 0.093
Decoding with hotwords
./build/bin/sherpa-onnx-offline \
--encoder=exp-zh/encoder-epoch-99-avg-1.onnx \
--decoder=exp-zh/decoder-epoch-99-avg-1.onnx \
--joiner=exp-zh/joiner-epoch-99-avg-1.onnx \
--tokens=exp-zh/tokens.txt \
--decoding-method=modified_beam_search \
--modeling-unit=cjkchar \
--hotwords-file=hotwords_cn.txt \
--hotwords-score=2.0 \
exp-zh/test_wavs/3.wav exp-zh/test_wavs/4.wav exp-zh/test_wavs/5.wav exp-zh/test_wavs/6.wav
OfflineRecognizerConfig(feat_config=OfflineFeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OfflineModelConfig(transducer=OfflineTransducerModelConfig(encoder_filename="exp-zh/encoder-epoch-99-avg-1.onnx", decoder_filename="exp-zh/decoder-epoch-99-avg-1.onnx", joiner_filename="exp-zh/joiner-$poch-99-avg-1.onnx"), paraformer=OfflineParaformerModelConfig(model=""), nemo_ctc=OfflineNemoEncDecCtcModelConfig(model=""), whisper=OfflineWhisperModelConfig$encoder="", decoder="", language="", task="transcribe"), tdnn=OfflineTdnnModelConfig(model=""), tokens="exp-zh/tokens.txt", num_threads=2, debug=False, provider="cpu", model_type=""), lm_config=OfflineLMConfig(model="", scale=0.5), decoding_method="modified_beam_search", max_active$paths=4, hotwords_file=hotwords_cn.txt, hotwords_score=2)
Creating recognizer ...
Started
Done!
exp-zh/test_wavs/3.wav
{"text":"文森特卡索是全球知名的法国性格派演员","timestamps":"[0.00, 0.16, 0.64, 1.28, 1.64, 2.04, 2.60, 2.88, 3.20, 3.52, 3.92, 4.40, 4.68, 5.12, 5.44, 6.36, $.96, 7.32]","tokens":["文","森","特","卡","索","是","全","球","知","名","的","法","国","性","格","派","演","员"]}
----
exp-zh/test_wavs/4.wav
{"text":"蒋有伯被拍到带着女儿出游","timestamps":"[0.00, 0.12, 0.80, 1.36, 1.76, 2.08, 2.28, 2.68, 2.92, 3.16, 3.44, 3.80]","tokens":["蒋","有","伯","被","拍",$
到","带","着","女","儿","出","游"]}
----
exp-zh/test_wavs/5.wav
{"text":"周望君就落实空物价","timestamps":"[0.00, 0.12, 0.80, 1.24, 1.56, 1.96, 2.68, 3.08, 3.32]","tokens":["周","望","君","就","落","实","空","物","价"]}
----
exp-zh/test_wavs/6.wav
{"text":"朱丽楠在上市见面会上表示","timestamps":"[0.00, 0.12, 0.80, 1.12, 1.44, 1.68, 1.92, 2.16, 2.36, 2.60, 2.84, 3.12]","tokens":["朱","丽","楠","在","上",$
市","见","面","会","上","表","示"]}
----
num threads: 2
decoding method: modified_beam_search
max active paths: 4
Elapsed seconds: 1.810 s
Real time factor (RTF): 1.810 / 20.328 = 0.089
Hint
文森特卡所 -> 文森特卡索
周望军 -> 周望君
朱立南 -> 朱丽楠
蒋友伯 -> 蒋有伯
Python api
Decoding without hotwords
python python-api-examples/offline-decode-files.py \
--encoder exp-zh/encoder-epoch-99-avg-1.onnx \
--decoder exp-zh/decoder-epoch-99-avg-1.onnx \
--joiner exp-zh/joiner-epoch-99-avg-1.onnx \
--tokens exp-zh/tokens.txt \
--decoding-method modified_beam_search \
exp-zh/test_wavs/3.wav exp-zh/test_wavs/4.wav exp-zh/test_wavs/5.wav exp-zh/test_wavs/6.wav
The output is:
Started!
Done!
exp-zh/test_wavs/3.wav
文森特卡所是全球知名的法国性格派演员
----------
exp-zh/test_wavs/4.wav
蒋友伯被拍到带着女儿出游
----------
exp-zh/test_wavs/5.wav
周望军就落实控物价
----------
exp-zh/test_wavs/6.wav
朱立南在上市见面会上表示
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 20.328 s
Elapsed time: 2.653 s
Real time factor (RTF): 2.653/20.328 = 0.131
Decoding with hotwords
python python-api-examples/offline-decode-files.py \
--encoder exp-zh/encoder-epoch-99-avg-1.onnx \
--decoder exp-zh/decoder-epoch-99-avg-1.onnx \
--joiner exp-zh/joiner-epoch-99-avg-1.onnx \
--tokens exp-zh/tokens.txt \
--decoding-method modified_beam_search \
--modeling-unit=cjkchar \
--hotwords-file hotwords_cn.txt \
--hotwords-score 2.0 \
exp-zh/test_wavs/3.wav exp-zh/test_wavs/4.wav exp-zh/test_wavs/5.wav exp-zh/test_wavs/6.wav
The output is:
Started!
Done!
exp-zh/test_wavs/3.wav
文森特卡索是全球知名的法国性格派演员
----------
exp-zh/test_wavs/4.wav
蒋有伯被拍到带着女儿出游
----------
exp-zh/test_wavs/5.wav
周望君就落实空物价
----------
exp-zh/test_wavs/6.wav
朱丽楠在上市见面会上表示
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 20.328 s
Elapsed time: 2.636 s
Real time factor (RTF): 2.636/20.328 = 0.130
Hint
文森特卡所 -> 文森特卡索
周望军 -> 周望君
朱立南 -> 朱丽楠
蒋友伯 -> 蒋有伯
Modeling unit is cjkchar+bpe
Download the model
cd /path/to/sherpa-onnx
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20.tar.bz2
tar xvf sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20.tar.bz2
rm sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20.tar.bz2
ln -s sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20 exp-mixed
Export bpe.vocab if you can’t find bpe.vocab in the model directory.
python script/export_bpe_vocab.py --bpe-model exp/bpe.model
The hotwords_mix.txt contains:
礼拜二
频繁
C++ api
Decoding without hotwords
./build/bin/sherpa-onnx \
--encoder=exp-mixed/encoder-epoch-99-avg-1.onnx \
--decoder=exp-mixed/decoder-epoch-99-avg-1.onnx \
--joiner=exp-mixed/joiner-epoch-99-avg-1.onnx \
--decoding-method=modified_beam_search \
--tokens=exp-mixed/tokens.txt \
exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
The output is:
/star-kw/kangwei/code/sherpa-onnx/sherpa-onnx/csrc/parse-options.cc:Read:361 ./build/bin/sherpa-onnx --encoder=exp-mixed/encoder-epoch-99-avg-1.onnx --decoder=exp-mixed/decoder-epoch-99-avg-1.onnx --joiner=exp-mixed/joiner-epoch-99-avg-1.onnx --decoding-method=modified_beam_search --tokens=exp-mixed/tokens.txt exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
OnlineRecognizerConfig(feat_config=FeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OnlineModelConfig(transducer=OnlineTransducerModelConfig(encoder="exp-mixed/encoder-epoch-99-avg-1.onnx", decoder="exp-mixed/decoder-epoch-99-avg-1.onnx", joiner="exp-mixed/joiner-epoch-99-avg-1.onnx"), paraformer=OnlineParaformerModelConfig(encoder="", decoder=""), tokens="exp-mixed/tokens.txt", num_threads=1, debug=False, provider="cpu", model_type=""), lm_config=OnlineLMConfig(model="", scale=0.5), endpoint_config=EndpointConfig(rule1=EndpointRule(must_contain_nonsilence=False, min_trailing_silence=2.4, min_utterance_length=0), rule2=EndpointRule(must_contain_nonsilence=True, min_trailing_silence=1.2, min_utterance_length=0), rule3=EndpointRule(must_contain_nonsilence=False, min_trailing_silence=0, min_utterance_length=20)), enable_endpoint=True, max_active_paths=4, hotwords_score=1.5, hotwords_file="", decoding_method="modified_beam_search")
exp-mixed/test_wavs/0.wav
Elapsed seconds: 3, Real time factor (RTF): 0.3
昨天是 MONDAY TODAY IS LIBR THE DAY AFTER TOMORROW是星期三
{"is_final":false,"segment":0,"start_time":0.0,"text":"昨天是 MONDAY TODAY IS LIBR THE DAY AFTER TOMORROW是星期三","timestamps":"[0.64, 1.04, 1.60, 2.08, 2.20, 2.40, 4.16, 4.40, 4.88, 5.56, 5.80, 6.16, 6.84, 7.12, 7.44, 8.04, 8.16, 8.24, 8.28, 9.04, 9.40, 9.64, 9.88]","tokens":["昨","天","是"," MO","N","DAY"," TO","DAY"," IS"," LI","B","R"," THE"," DAY"," AFTER"," TO","M","OR","ROW","是","星","期","三"]}
exp-mixed/test_wavs/2.wav
Elapsed seconds: 1.7, Real time factor (RTF): 0.37
是不是平凡的啊不认识记下来 FREQUENTLY频繁的
{"is_final":false,"segment":0,"start_time":0.0,"text":"是不是平凡的啊不认识记下来 FREQUENTLY频繁的","timestamps":"[0.00, 0.40, 0.52, 0.96, 1.08, 1.28, 1.48, 1.68, 1.84, 2.00, 2.24, 2.36, 2.52, 2.68, 2.92, 3.00, 3.12, 3.32, 3.64, 3.96, 4.36]","tokens":["是","不","是","平","凡","的","啊","不","认","识","记","下","来"," F","RE","QU","ENT","LY","频","繁","的"]}
Decoding with hotwords
./build/bin/sherpa-onnx \
--encoder=exp-mixed/encoder-epoch-99-avg-1.onnx \
--decoder=exp-mixed/decoder-epoch-99-avg-1.onnx \
--joiner=exp-mixed/joiner-epoch-99-avg-1.onnx \
--decoding-method=modified_beam_search \
--tokens=exp-mixed/tokens.txt \
--modeling-unit=cjkchar+bpe \
--bpe-vocab=exp/bpe.vocab \
--hotwords-file=hotwords_mix.txt \
--hotwords-score=2.0 \
exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
The output is:
/star-kw/kangwei/code/sherpa-onnx/sherpa-onnx/csrc/parse-options.cc:Read:361 ./build/bin/sherpa-onnx --encoder=exp-mixed/encoder-epoch-99-avg-1.onnx --decoder=exp-mixed/decoder-epoch-99-avg-1.onnx --joiner=exp-mixed/joiner-epoch-99-avg-1.onnx --decoding-method=modified_beam_search --tokens=exp-mixed/tokens.txt --tokens-type=cjkchar+bpe --bpe-model=exp-mixed/bpe.model --hotwords-file=hotwords_mix.txt --hotwords-score=2.0 exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
OnlineRecognizerConfig(feat_config=FeatureExtractorConfig(sampling_rate=16000, feature_dim=80), model_config=OnlineModelConfig(transducer=OnlineTransducerModelConfig(encoder="exp-mixed/encoder-epoch-99-avg-1.onnx", decoder="exp-mixed/decoder-epoch-99-avg-1.onnx", joiner="exp-mixed/joiner-epoch-99-avg-1.onnx"), paraformer=OnlineParaformerModelConfig(encoder="", decoder=""), tokens="exp-mixed/tokens.txt", num_threads=1, debug=False, provider="cpu", model_type=""), lm_config=OnlineLMConfig(model="", scale=0.5), endpoint_config=EndpointConfig(rule1=EndpointRule(must_contain_nonsilence=False, min_trailing_silence=2.4, min_utterance_length=0), rule2=EndpointRule(must_contain_nonsilence=True, min_trailing_silence=1.2, min_utterance_length=0), rule3=EndpointRule(must_contain_nonsilence=False, min_trailing_silence=0, min_utterance_length=20)), enable_endpoint=True, max_active_paths=4, hotwords_score=2, hotwords_file="hotwords_mix.txt", decoding_method="modified_beam_search")
exp-mixed/test_wavs/0.wav
Elapsed seconds: 3.2, Real time factor (RTF): 0.32
昨天是 MONDAY TODAY IS礼拜二 THE DAY AFTER TOMORROW是星期三
{"is_final":false,"segment":0,"start_time":0.0,"text":"昨天是 MONDAY TODAY IS礼拜二 THE DAY AFTER TOMORROW是星期三","timestamps":"[0.64, 1.04, 1.60, 2.08, 2.20, 2.40, 4.16, 4.40, 4.88, 5.56, 5.68, 6.00, 6.84, 7.12, 7.44, 8.04, 8.16, 8.24, 8.28, 9.04, 9.40, 9.64, 9.88]","tokens":["昨","天","是"," MO","N","DAY"," TO","DAY"," IS","礼","拜","二"," THE"," DAY"," AFTER"," TO","M","OR","ROW","是","星","期","三"]}
exp-mixed/test_wavs/2.wav
Elapsed seconds: 1.9, Real time factor (RTF): 0.4
是不是频繁的啊不认识记下来 FREQUENTLY频繁的
{"is_final":false,"segment":0,"start_time":0.0,"text":"是不是频繁的啊不认识记下来 FREQUENTLY频繁的","timestamps":"[0.00, 0.40, 0.52, 0.96, 1.08, 1.28, 1.48, 1.68, 1.84, 2.00, 2.24, 2.36, 2.52, 2.68, 2.92, 3.00, 3.12, 3.32, 3.64, 3.96, 4.36]","tokens":["是","不","是","频","繁","的","啊","不","认","识","记","下","来"," F","RE","QU","ENT","LY","频","繁","的"]}
Hint
LIBR -> 礼拜二
平凡 -> 频繁
Python api
Decoding without hotwords
python python-api-examples/online-decode-files.py \
--encoderexp-mixed/encoder-epoch-99-avg-1.onnx \
--decoder exp-mixed/decoder-epoch-99-avg-1.onnx \
--joiner exp-mixed/joiner-epoch-99-avg-1.onnx \
--decoding-method modified_beam_search \
--tokens exp-mixed/tokens.txt
exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
The output is:
Started!
Done!
exp-mixed/test_wavs/0.wav
昨天是 MONDAY TODAY IS LIBR THE DAY AFTER TOMORROW是星期三
----------
exp-mixed/test_wavs/2.wav
是不是平凡的啊不认识记下来 FREQUENTLY频繁的
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 14.743 s
Elapsed time: 3.052 s
Real time factor (RTF): 3.052/14.743 = 0.207
Decoding with hotwords
python python-api-examples/online-decode-files.py \
--encoder exp-mixed/encoder-epoch-99-avg-1.onnx \
--decoder exp-mixed/decoder-epoch-99-avg-1.onnx \
--joiner exp-mixed/joiner-epoch-99-avg-1.onnx \
--decoding-method modified_beam_search \
--tokens exp-mixed/tokens.txt \
--modeling-unit cjkchar+bpe \
--bpe-vocab exp-mixed/bpe.vocab \
--hotwords-file hotwords_mix.txt \
--hotwords-score 2.0 \
exp-mixed/test_wavs/0.wav exp-mixed/test_wavs/2.wav
The output is:
Started!
Done!
exp-mixed/test_wavs/0.wav
昨天是 MONDAY TODAY IS礼拜二 THE DAY AFTER TOMORROW是星期三
----------
exp-mixed/test_wavs/2.wav
是不是频繁的啊不认识记下来 FREQUENTLY频繁的
----------
num_threads: 1
decoding_method: modified_beam_search
Wave duration: 14.743 s
Elapsed time: 3.060 s
Real time factor (RTF): 3.060/14.743 = 0.208
Hint
LIBR -> 礼拜二
平凡 -> 频繁